
Title: Robustness at Inference: Towards Explainability, Uncertainty, and Intervenability
Duration: Half-Day event
TUTORIAL SLIDES: [HERE]
Presented by: Ghassan AlRegib, and Mohit Prabhushankar
Georgia Institute of Technology
https://alregib.ece.gatech.edu
alregib@gatech.edu, mohit.p@gatech.edu
Speakers

Ghassan AlRegib is currently the John and McCarty Chair Professor in the School of Electrical and Computer Engineering at the Georgia Institute of Technology. He received the ECE Outstanding Junior Faculty Member Award, in 2008 and the 2017 Denning Faculty Award for Global Engagement. His research group, the Omni Lab for Intelligent Visual Engineering and Science (OLIVES) works on research projects related to machine learning, image and video processing, image and video understanding, seismic interpretation, machine learning for ophthalmology, and video analytics. He has participated in several service activities within the IEEE. He served as the TP co-Chair for ICIP 2020. He is an IEEE Fellow.

Mohit Prabhushankar received his Ph.D. degree in electrical engineering from the Georgia Institute of Technology (Georgia Tech), Atlanta, Georgia, 30332, USA, in 2021. He is currently a Postdoctoral Research Fellow in the School of Electrical and Computer Engineering at the Georgia Institute of Technology in the Omni Lab for Intelligent Visual Engineering and Science (OLIVES). He is working in the fields of image processing, machine learning, active learning, healthcare, and robust and explainable AI. He is the recipient of the Best Paper award at ICIP 2019 and Top Viewed Special Session Paper Award at ICIP 2020. He is the recipient of the ECE Outstanding Graduate Teaching Award, the CSIP Research award, and of the Roger P Webb ECE Graduate Research Excellence award, all in 2022.
Tutorial Description
General Description of Content:
Neural networks provide generalizable and task independent representation spaces that have garnered widespread applicability in image understanding applications. The complicated semantics of feature interactions within image data has been broken down into a set of non-linear functions, convolution parameters, attention, as well as multi-modal inputs among others. The complexity of these operations has introduced multiple vulnerabilities within neural network architectures. These vulnerabilities include adversarial samples, confidence calibration issues, and catastrophic forgetting among others. Given that AI promises to herald the fourth industrial revolution, it is critical to understand and overcome these vulnerabilities. Doing so requires creating robust neural networks that drive the AI systems. Defining robustness, however, is not trivial. Simple measurements of invariance to noise and perturbations are not applicable in real life settings. In this tutorial, we provide a human-centric approach to understanding robustness in neural networks that allow AI to function in society. Doing so allows us to state the following: 1) All neural networks must provide contextual and relevant explanations to humans, 2) Neural networks must know when and what they don’t know, 3) Neural Networks must be amenable to being intervened upon by humans at decision-making stage. These three statements call for robust neural networks to be explainable, equipped with uncertainty quantification, and be intervenable.
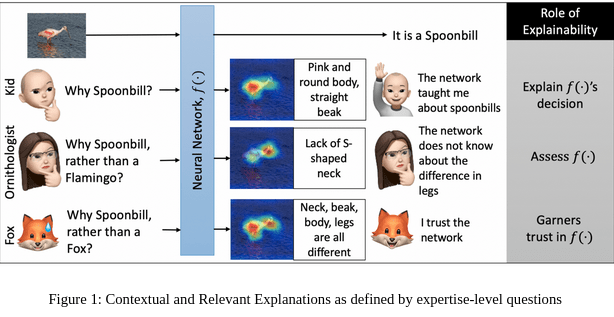
We provide a probabilistic post-hoc analysis of explainability, uncertainty, and intervenability. Post-hoc implies that a decision has already been made. A simple example of post-hoc contextual and relevant explanations is shown in Fig. 1. Given a well-trained neural network, regular explanations answer the question of `Why spoonbill?’ by highlighting the body of the bird. However, a more relevant question can be `Why spoonbill, rather than a Flamingo?’. Such a question requires the questioner to be aware of the features of a flamingo. If the network shows that the difference is in the lack of an S-shaped neck, then the questioner will be satisfied with the contextual answer provided. Contextual explanations build trust as well as assesses the neural network apart from explaining the decisions. In larger context, the goal of explainability must be to satisfy multiple stakeholders at various levels of expertise. This includes researchers, engineers, policymakers, and everyday users among others. In this tutorial, we expound on a gradient-based methodology that provides all the above explanations without requiring any retraining. Once a neural network is trained, it acts as a knowledge base through which different types of gradients can be used to traverse adversarial, contrastive, explanatory, counterfactual representation spaces. Apart from explanations, we demonstrate the utility these gradients to define uncertainty and intervenability. Several image understanding and robustness applications including anomaly, novelty, adversarial, and out-of-distribution image detection, image quality assessment, and noise recognition experiments among others will be discussed. In this tutorial, we examine the types, visual meanings, and interpretations of robustness as a human-centric measure of the utility of large-scale neural networks.
Tutorial Outline
The tutorial is composed of four major parts. Part 1 discusses some recent surprising results regarding training neural networks with out-of-distribution (OOD) data, the conclusions of which are that it is not always clear when and how to use OOD in a big data setup. We use this as a motivation for the course material. Part 2 introduces the basic mathematical framework for each one of Explainability, Uncertainty, and Intervenability. Part 3 discusses Explainability and Uncertainty while part 4 discusses Intervenability exclusively. The outline and the presenter for each part is shown below.
Part 1: Inference in Neural Networks
Part 2: Explainability at Inference
Part 3: Uncertainty at Inference
Part 4: Intervenability at Inference
Part 5: Conclusions and Future Directions
Target Audience
This tutorial is intended for graduate students, researchers and engineers working in different topics related to visual information processing and robust machine learning. In the most recent previous offering of the tutorial at IEEE ICIP 2023, we had 40 attendees.
Relations with similar tutorials/short courses
This is a timely tutorial that emphasizes the robustness of neural networks in terms of human-centric measures which aids in their widespread applicability. Explainability and uncertainty research fields are accompanied by a large body of literature that analyze decisions. Intervenability, on the other hand, has gained recent prominence due its inclusion in the GDPR regulations and a surge in prompting-based neural network architectures. Similar tutorials in the past few years include:
- CVPR 2023, Trustworthy AI in the era of Foundation Models [Link]
- ICCV 2023, The many faces of Reliability of Deep Learning for Real-World Deployment [Link]
- CVPR 2022, Evaluating Models beyond the Textbook [Link]
- CVPR 2021, Interpretable Machine Learning for Computer Vision [Link]
- CVPR 2021, Practical Adversarial Robustness in Deep Learning: Problems and Solutions, [Link]
Selected talks, tutorials, and content from presenters
- Short Course: G. AlRegib and M. Prabhushankar, “Visual Explainability in Machine Learning,” IEEE Signal Processing Society Short Course, Virtual, Dec. 5-7, 2023. [Website]
- Tutorial: G. AlRegib and M. Prabhushankar, “A Holistic View of Perception in Intelligent Vehicles,” at IEEE Intelligent Vehicle Symposium (IV 2023), Anchorage, AK, USA, Jun. 04, 2023. ,[PDF]. [Video Link]
- Tutorial: G. AlRegib and M. Prabhushankar, “A Multi-Faceted View of Gradients in Neural Networks: Extraction, Interpretation and Applications in Image Understanding,” at IEEE International Conference on Image Processing (ICIP 2023), Kuala Lumpur, Malaysia, Oct. 08, 2023. [PDF].
- Talk: M. Prabhushankar, “Towards Robust Neural Networks: Explainability, Uncertainty, Intervenability”, at AI4OPT Seminar Series, Atlanta, GA, Aug. 24, 2023, [Video Link]
- Talk: G. AlRegib, “Artificial Intelligence,” at Scientific Sense ® Podcast, Invited, Mar. 9 2021. [Podcast Link]
Selected Publications
[1] AlRegib, Ghassan, and Mohit Prabhushankar. “Explanatory Paradigms in Neural Networks: Towards relevant and contextual explanations.” IEEE Signal Processing Magazine 39.4 (2022): 59-72.
[2] M. Prabhushankar, and G. AlRegib, “Introspective Learning : A Two-Stage Approach for Inference in Neural Networks,” in Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA,, Nov. 29 – Dec. 1 2022.
[3] Kwon, G., Prabhushankar, M., Temel, D., & AlRegib, G. (2020). Backpropagated gradient representations for anomaly detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16, Springer International Publishing.
[4] M. Prabhushankar and G. AlRegib, “Extracting Causal Visual Features for Limited Label Classification,” IEEE International Conference on Image Processing (ICIP), Anchorage, AK, Sept 2021.
[5] Selvaraju, Ramprasaath R., et al. “Grad-cam: Visual explanations from deep networks via gradient-based localization.” Proceedings of the IEEE international conference on computer vision. 2017.
[6] Prabhushankar, M., Kwon, G., Temel, D., & AlRegib, G. (2020, October). Contrastive explanations in neural networks. In 2020 IEEE International Conference on Image Processing (ICIP) (pp. 3289-3293). IEEE.
[7] G. Kwon, M. Prabhushankar, D. Temel, and G. AlRegib, “Novelty Detection Through Model-Based Characterization of Neural Networks,” in IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, Oct. 2020.
[8] J. Lee and G. AlRegib, “Gradients as a Measure of Uncertainty in Neural Networks,” in IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, Oct. 2020.
[9] M. Prabhushankar*, G. Kwon*, D. Temel and G. AIRegib, “Distorted Representation Space Characterization Through Backpropagated Gradients,” 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 2019, pp. 2651-2655. (* : equal contribution, Best Paper Award (top 0.1%))
[10] J. Lee, M. Prabhushankar, and G. AlRegib, “Gradient-Based Adversarial and Out-of-Distribution Detection,” in International Conference on Machine Learning (ICML) Workshop on New Frontiers in Adversarial Machine Learning, Baltimore, MD, Jul., 2022.
